
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 리트코드
- 동적 계획법
- vscode
- 프로그래머스
- TypeScript
- DFS
- Javascript
- Data Structure
- Algorithm
- git
- Python
- db
- network
- react
- 그레이들
- Database
- 안드로이드
- 알고리즘
- Graph
- LeetCode
- CS
- BFS
- DP
- 다이나믹 프로그래밍
- frontend
- Redux
- VIM
- java
- 백준
- 자바
- Today
- Total
늘 겸손하게
딥러닝 이미지 분류 모델 개발 일지 - 1 본문
안녕하세요 besforyou 입니다.
산학연계 프로젝트 - 수기 서명 패턴 분류 프로젝트를 개발하는 중에 공부한 딥러닝 이미지 분류 모델 기초 지식과 일지입니다.
아래 글은 이미지 분류 모델을 개발하는데 필요한 배경 지식입니다.
컨볼루션 신경망 ( Convolution Neural Network )
이미지 분류 모델입니다.
- 컨볼루션 적용
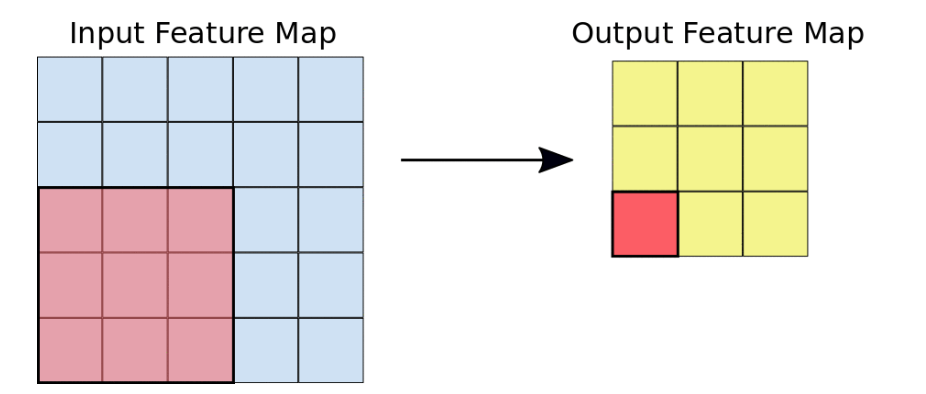
n x n 컨볼루션 필터를 각 픽셀에 적용하여 사이즈는 원본보다 작지만 원본의 특징들을 담고있는 Feature map(특징 지도)을 생성합니다.
2.ReLU ( Rectified Linear Unit )
각각의 컨볼루션 작업이 적용된 후, CNN은 모델에 비선형성을 주기 위해 ReLU transformation을 콘볼루션된 특징에 적용합니다.
예로, ReLU 함수 F(x) = max(0, x) 는 x > 0 인 값은 x를 반환하고 x ≤ 0 인 값은 0을 반환합니다.
3. Pooling
ReLU가 적용된 후, 컨볼루션이 적용된 특징 지도의 차원 수를 줄이기 위해 Pooling을 적용합니다.
Pooling이 적용되어 특징 지도의 크기와 차원은 줄어들지만 핵심적인 특징은 사라지지 않고 보존됩니다.
이 과정에 사용되는 알고리즘 중 하나가 max pooling 입니다.
Max pooling은 컨볼루션과 비슷하게 적용됩니다. 같은 길이의 타일들 중 가장 큰 값만 보존된채로 특징 지도가 추출됩니다.
Max pooling operation은 두 개의 인자를 받습니다.
- Max pooling 필터의 Size
- Stride : Max pooling 필터가 몇칸 움직일지
Size 2 , Stride 2인 Max pooling 예시




Fully Connected Layers
컨볼루션 신경망 네트워크 맨 마지막에는 하나 혹은 그 이상의 Fully connected layer들이 존재한다.
여기서 fully connected layer란 첫 번째 레이어의 모든 노드가 두 번째 레이어의 모든 노드에 연결된것을 말한다. 이 layer들의 역할은 컨볼루션을 통해 추출된 특징들을 토대로 들어온 이미지의를 분류하는것이다.
일반적으로 fully connected layer들의 마지막 부분에는 softmax activation function이 존재한다. 이 함수의 기능은 들어온 이미지에 대한 분류 예측 결과를 0~1 사이의 값으로 바꾸어 주는 기능이다.
분류기 생성 Exercise - cat or dog
단 위 예제는 오버피팅된 상태.
오버피팅이란 학습 데이터에 학습이 지나치게 잘 되어, 학습 데이터가 아닌 데이터에는 좋지 못한 성능을 보이는 상태를 말한다.
Prevent Overfitting - 오버피팅 방지
모든 머신 러닝 모델과 같이 CNN의 중요한 고민은 overfitting이다. 오버피팅이란 학습이 학습 데이터에 너무 맞춰져 새로운 데이터에는 좋지 못한 성능을 나타내는것을 말한다. 이를 방지하기 위한 방법에는 두 가지가 존재한다.
- Data augmentation : 데이터 증강
이미 존재하는 이미지에 무작위적인 변형을 가하여 인공적으로 다양하고 많은 훈련 샘플을 생성하는 일을 말한다.
Data augmentation은 훈련 데이터 집합의 크기가 작을때 유용하다.
- Dropout regularization : 드롭아웃 기법
훈련 진행 중에 무작위로 몇 개의 훈련 데이터를 버리는것
cat or dog CNN 모델에 augmentation and dropout regularization 적용 예제
image_classification_part2.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
위 자료는 이미지 분류기에 대한 기초 지식을 얻는데는 도움이 되었지만 예제는 이진 분류기를 만드는 예제여서 더 많은 자료가 필요했다.
그래서 찾은것이 TensorFlow Core의 이미지 분류
https://www.tensorflow.org/tutorials/images/classification?hl=ko
이미지 분류 | TensorFlow Core
이미지 분류 이 튜토리얼은 꽃 이미지를 분류하는 방법을 보여줍니다. keras.Sequential 모델을 사용하여 이미지 분류자를 만들고 preprocessing.image_dataset_from_directory를 사용하여 데이터를 로드합니다.
www.tensorflow.org
위의 예시는 이미지가 개, 고양이 두 가지만을 구분해주는 이진 분류기였지만 위 글은 5개의 꽃 종류에 따라 이미지를 분류해주는 분류 모델이어서 우리가 만들 프로젝트에 적합한 자료라고 생각됩니다.
'Computer Science' 카테고리의 다른 글
| CS - HTTP (0) | 2022.05.29 |
|---|---|
| CS - 호스팅이란? (0) | 2022.05.28 |
| 주소창에 DNS를 입력하면 일어나는 일 - CS (0) | 2022.05.28 |
| 인터넷 작동 원리 (0) | 2022.05.28 |
| VCS - Version Control System (0) | 2022.02.14 |
